
理论
在这之前,我们要先理解局部性
局部性
一个具有局部性的程序,倾向于引用(最近引用过的数据)的临近数据,或者最近引用的数据本身。这种倾向叫局部性。前者叫空间局部性,后者叫时间局部性。
一般来说,局部性好的程序运行得更快。
计算机的各个层次都有局部性,包括硬件,操作系统,应用程序等。
假设在c程序中有一个数组,它在内存中占据了一片连续的空间。如果有一个for循环,顺序遍历数组的每个元素,那我们称这个函数具有步长为1的引用模式(1指相对于数组元素大小),又称顺序引用模式。在一个数组中,每隔k个元素进行访问,称步长为k的访问模式。k越大,空间局部性越差。
评价一个程序的局部性:
- 重复引用相同变量的程序有良好的时间局部性。
- 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好。具有步长为l 的引用模式的程序有很好的空间局部性。在内存中以大步长跳来跳去的程序空间局部性会很差。
- 对于取指令来说,循环有好的时间和空间局部性。循环体越小,循环迭代次数越 多,局部性越好。
出自《csapp第三版》418页
高速缓存存储器(cache)
早期cpu寄存器直接从内存中读取数据,但由于技术不断发展,cpu速度越来越快,但是DRAM的速度受限,因此在这两者之间插入了一个高速缓存存储器称为L1高速缓存(一级缓存)。之后又在L1和主存之间插入L2,在L2和主存之间插入L3。
我们假设cpu和主存之间只有一个L1
高速缓存的结构和工作原理
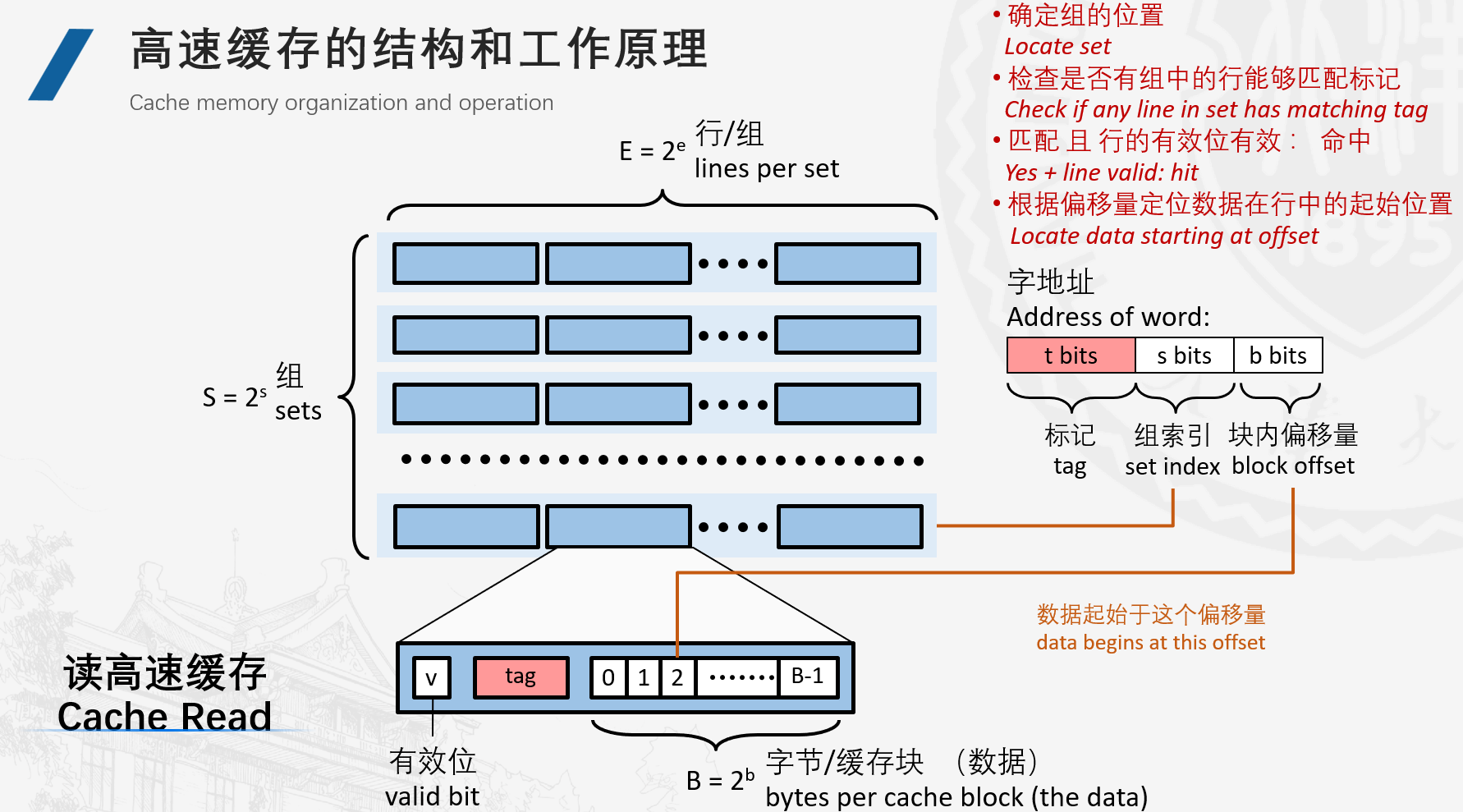
如图所示,考虑一个计算机系统,其中每个存储器地址有m位(对应图上字地址),形成$M = 2^{m} $个不同的地址,这样的一个cache被组织为$S = 2^{s} $个set,每个set包含$E = 2^{e} $个line,每个line由一个有效位,一个tag,一个block组成。其中一个block有$B = 2^{b} $个字节。而tag(标记)就剩下了t = m - s - b个位来表示。
具体如何查找,请看图中红字。
每个组只有一行(E = 1)的高速缓存称为直接映射高速缓存。
直接映射高速缓存
这种情况下比较简单,当cpu执行一条内存读取指令时,首先检查是否命中
检查命中分两步:组匹配,行匹配。
由于直接映射高速缓存只有一行,那么行匹配会非常容易,只有有效位被设置,且tag也匹配时,才命中。
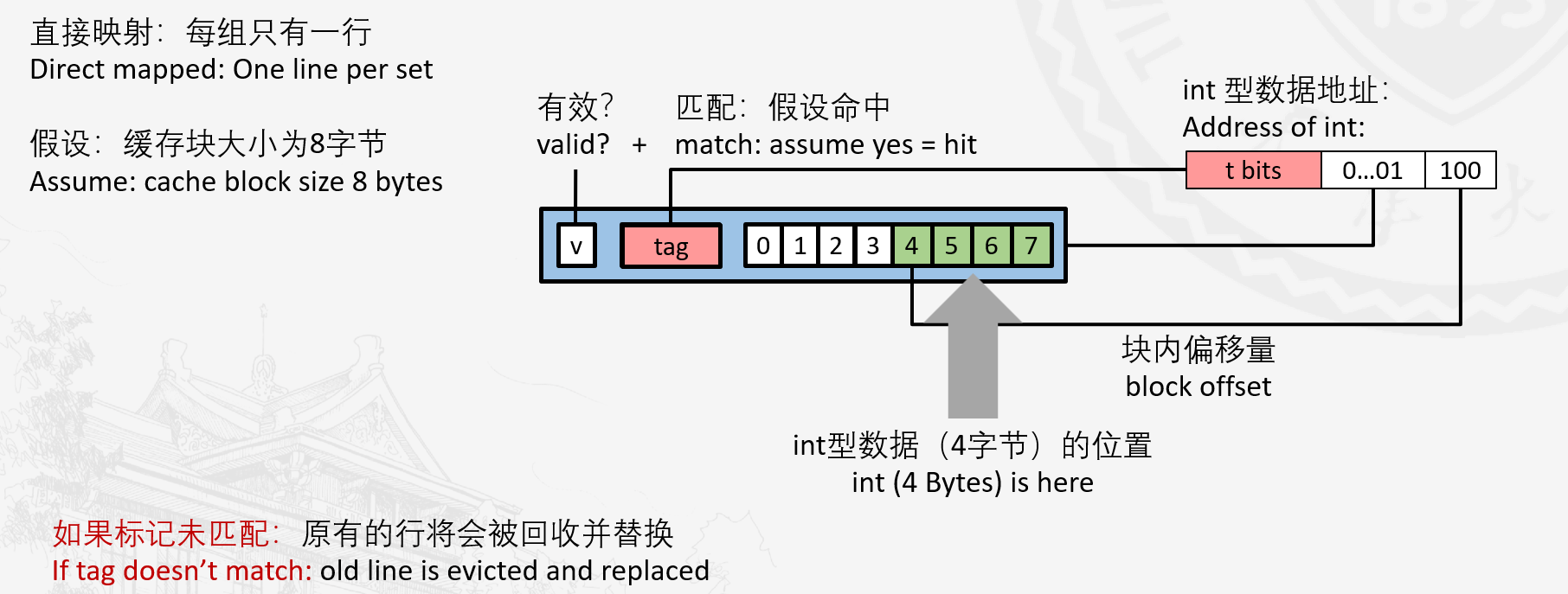
如果命中,就去偏移量的地方取数据,返回寄存器。
如果不命中,就向L2发出请求,…以此类推,最终取到被请求的block(数据复制时,以块为基本单元,所以一来就是一整个block)。然后将块存在这一组(set)下的某一行中,并设置tag。如果一个set中全都是有效行,那就驱逐出一个行。当然,这对于直接映射很简单,因为每个set只有一个line。
我们最好手动模拟一下这个过程,对应ppt课件第11张有动画,以及黑皮书第三版429页,以加深理解。
这里再补充一下,这个用于从cache中检索的地址就是我们理解的那个地址,即指针值(在内存中的地址)。
冲突不命中
对应黑皮书431页
简单说就是有两个数组float x[8] 和 float y[8],寄存器要先访问x[0],那就将包含了x[0] ~ x[3]的块加载到cache,然后访问y[0],由于y[0] ~ y[3]的块的组地址和x[0] ~ x[3]相同,于是就将y[0] ~ y[3]加载,x[0] ~ x[3]被覆盖。然后又要访问x[1],y[1]…导致反复加载和驱逐相同的block,这就是冲突不命中。因为我们在x和y的block之间抖动(thrash)。
即使程序有好的空间局部性,且cache也有足够空间,但是由于冲突不命中,导致速度下降2-3倍。
解决方法就是在两个数组尾部放B个字节的填充。例如这个例子,cache的B为16,那我们在放4个float元素,即float x[12],float y[12]就可以解决了。
为什么使用中间的位来做高速缓存索引
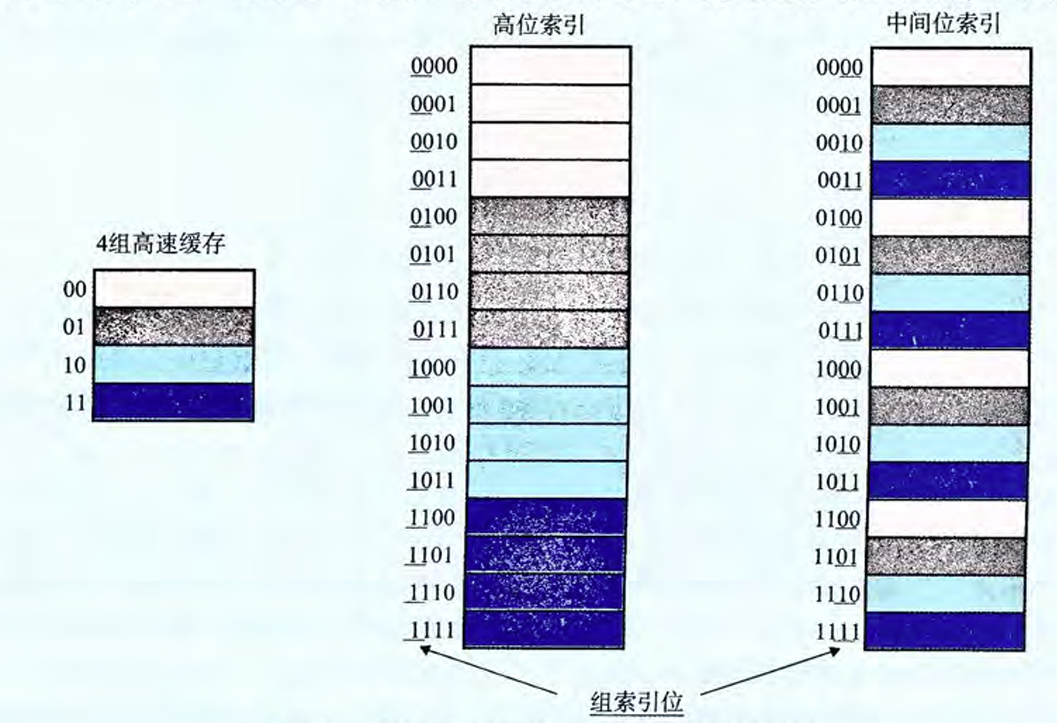
如图,这个cache是直接映射的
假设有一个程序,顺序扫描整个数组,如果用高位做索引,那么扫描完了0000块进入相邻的0001块要重新放逐和加载。
如果是中间位做索引,那么相邻的块就都存入cache,可以更快取数据
组相联高速缓存
每个set的line数大于一,且set数一般大于一
检查命中时,行匹配比上一种复杂,它要检查所有line的有效位和tag。
命中时取数据同上
不命中时,cache要从下一级取出这个block,那么要替换哪一行呢?
有空行最好,没有就要使用某种策略来替换。
最简单的策略是随机替换,其他的替换策略利用了局部性原理,但是这些策略很难在代码中利用,而是用额外时间和硬件完成的。
比如说最不常用(LFU)策略,会替换过去某个时间段引用次数最少的那一行,而最近最少使用(LRU)策略会替换距最后一次访问时间最远的那个。
存储器层次越往下走,没有命中的代价越高,所以这是值得的。
全相联高速缓存
只有一个组,包含了所有行。
检查命中的组选择非常简单,但是行匹配的规模很大,而且这个匹配要想做简单不容易,因此这种cache只适合小的高速缓存。
写内存
如果写一个已经缓存的字w(写命中),在cache中更新后,写回内存有两种方法
- 直写:立即将块写回低一层中的副本(缺点是每次直写都引起总线流量)
- 写回:尽可能推迟更新,只有当这个块要被驱逐时才写回低一层(缺点是要维护一个修改位,表明是否被修改)
如果不命中
- 写分配:从低一层的缓存中加载这个块,然后更新它(缺点是每次不命中代价较大)
- 非写分配:直接写入低一层缓存
要编写一个高速缓存友好的程序,建议使用写回写分配(理由在书438页)

真实情况下的高速缓存层次结构
目前为止,我们一直在假设cache中存的都是数据,但事实上,cache中也保存指令。
保存数据的叫d-cache
保存指令的叫i-cache,通常是只读的,比较简单
同时保存数据和指令的叫统一高速缓存(unified cache)
衡量cache性能的指标
- 未命中率:未命中次数/总访问次数(L1:3% - 10%)
- 命中时间:将缓存数据发送到处理器的总时间,包括判断命中的时间(L1 : 1-2周期 L2:5 - 20周期)
- 未命中惩罚:由于未命中所需的额外访问数据时间(主存:50 - 200周期)
- 命中率基本不提,因为99%命中率的效率基本达到了97%命中率的两倍,所以还是看未命中率

高速缓存中各个参数对性能影响的分析,看书439页
高速缓存对程序性能的影响
这部分看ppt和书即可,以后有时间补。
实现
我们按照指导书上面的要求来实现cache
在/nemu/src/memory/memory.c中来实现
首先是数据结构
#define block_bytes 64 // 一个块的字节
#define cache_ways 8 // 几路组相连
#define cache_sets 1024/8 // cache的组数
/* cache的class */
typedef struct {
uint32_t tag; // 标记位
uint8_t block[block_bytes]; // 64个字节
bool valid; // valid bit
} block;
typedef struct set {
block blocks[cache_ways];
} set;
typedef struct cache {
/* 成员属性 */
set sets[cache_sets]; // 2**10个块
/* 成员函数 */
void (* init) (cache *this);
} cache;
void init_(cache x) {
int i, j;
for(i = 0; i < cache_sets; i++) {
for(j = 0; j < cache_ways; j++) {
x.sets[i].blocks[j].valid = 0;
}
}
}
我们可以定义的再规范一点,这样可以在实现L2的时候轻松一点。
然后在新文件中专门实现cache。
nemu/include/memory/cache.h
#ifndef __CACHE_H__
#define __CACHE_H__
#include "common.h"
/* block */
#define block_size_bit 6 // addr : 6位块内偏移
#define block_size 64 // 一个块的字节
typedef struct {
uint32_t tag; // 标记位(19位)
uint8_t block[block_size]; // 64个字节
bool valid, dirty; // 有效位 和 脏位
} block;
/* L1 cache
* write through & not write allocate
*/
#define l1_ways 8 // 8路组相连 1个set = 8个块
#define l1_sets_bit 7 // addr : 组号的位数
#define l1_sets (1024/8) // cache的组数 块数/8
block l1_cache[l1_sets][l1_ways];
uint64_t l1_t; // 计时变量
#define l1_tag_bit 19 //为什么是这个数,前文已经讲了
void init_cache();
#endif
感觉L1,L2同时写好一点,因为L1要从L2里面找。
,感觉之后没啥好讲的,就实现理论中说的功能就行了